


1·
5 months agoIt absolutely would be. It is, on the other hand, occasionly useful to be able to pop in and change a config file, many of which are actually Turing complete languages. What I do far more often, though, is SSH into remote, headless servers and write code there, which is exactly the same as doing it from a phone, only much more comfortable.




{kind=link}
{kind=link}
{kind=link}
Huh.
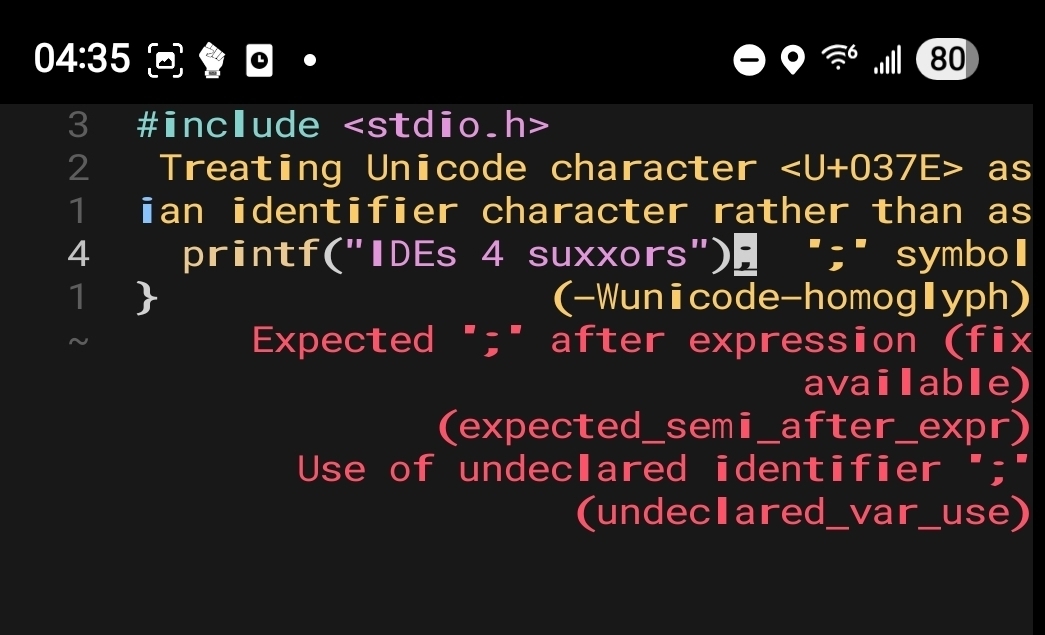
tar tfandunzip -l. I’m not sure I’d even bother to write a shell function to combine them, much less install software.Zips just exploding to files is so common, if you just
mkdir unzpd ; unzip -d unzpd file.zipit’s going to be right nearly all of the time. Same with tarballs always containing a directory; it’s just so common it’s barely worth checking.You write the tools you need, don’t get me wrong. This seems like, at most, a 10-line bash function, and even that seems excessive.
function pear() { case $1 in *.zip) unzip -l "$1" ;; *.tar.*) tar tf "$1" ;; esac }